
“ما وجدناه هو أن عملاء الذكاء الاصطناعي يمكنهم القيام بشيء كان صعبًا للغاية في السابق: بدءاً من النص الحر (مثل نسخة مقابلة مجهولة المصدر) يمكنهم الوصول إلى الهوية الكاملة للشخص،” قال سيمون ليرمان، المؤلف المشارك للورقة البحثية، لآرس. “هذه قدرة جديدة جدًا؛ تتطلب الأساليب السابقة لإعادة تحديد الهوية بشكل عام بيانات منظمة، ومجموعتي بيانات بمخطط مماثل يمكن ربطهما معًا.”
وعلى عكس الأساليب القديمة لتجريد الأسماء المستعارة، قال ليرمان، إن عملاء الذكاء الاصطناعي يمكنهم تصفح الويب والتفاعل معه بالعديد من الطرق نفسها التي يفعلها البشر. يمكنهم استخدام الاستدلال المحاكى لمطابقة الأفراد المحتملين. في إحدى التجارب، نظر الباحثون في الإجابات الواردة في استبيان أخذته الأنثروبولوجيا حول كيفية استخدام الأشخاص المختلفين للذكاء الاصطناعي في حياتهم اليومية. وباستخدام المعلومات المأخوذة من الإجابات، تمكن الباحثون من تحديد 7% من 125 مشاركًا بشكل إيجابي.
إخفاء الهوية من طرف إلى طرف من نسخة مقابلة واحدة (مع تغيير التفاصيل لحماية هوية الشخص المعني). قام وكيل LLM باستخراج إشارات هوية منظمة من إحدى المحادثات، وقام بالبحث بشكل مستقل في الويب لتحديد هوية الفرد المرشح، والتحقق من مطابقة المرشح لجميع المطالبات المستخرجة.
إخفاء الهوية من طرف إلى طرف من نسخة مقابلة واحدة (مع تغيير التفاصيل لحماية هوية الشخص المعني). قام وكيل LLM باستخراج إشارات هوية منظمة من إحدى المحادثات، وقام بالبحث بشكل مستقل في الويب لتحديد هوية الفرد المرشح، والتحقق من مطابقة المرشح لجميع المطالبات المستخرجة.
في حين أن معدل التذكر بنسبة 7% يعد منخفضًا نسبيًا، إلا أنه يوضح القدرة المتزايدة للذكاء الاصطناعي على التعرف على الأشخاص بناءً على المعلومات العامة جدًا التي قدموها. وقال ليرمان: “إن حقيقة أن الذكاء الاصطناعي يمكنه القيام بذلك على الإطلاق هي نتيجة جديرة بالملاحظة”. “ومع تحسن أنظمة الذكاء الاصطناعي، فمن المرجح أن تتحسن في العثور على المزيد والمزيد من الهويات.”
في تجربة ثانية، جمع الباحثون التعليقات التي تم الإدلاء بها في عام 2024 من موقع r/movies الفرعي وواحد على الأقل من خمسة مجتمعات أصغر: r/horror، وr/MovieSuggestions، وr/Letterboxd، وr/TrueFilm، وr/MovieDetails. وأظهرت النتائج أنه كلما زاد عدد الأفلام التي ناقشها المرشح، كان من الأسهل التعرف عليها. ويمكن التعرف على 3.1% في المتوسط من المستخدمين الذين يشاركون فيلمًا واحدًا بدقة 90%، و1.2% منهم بدقة 99%. ومن خلال مشاركة خمسة إلى تسعة أفلام، ارتفعت الدقة بنسبة 90% و99% إلى 8.4% و2.5% من المستخدمين على التوالي. وقد رفعت أكثر من 10 أفلام مشتركة النسبة إلى 48.1 بالمائة و17 بالمائة.
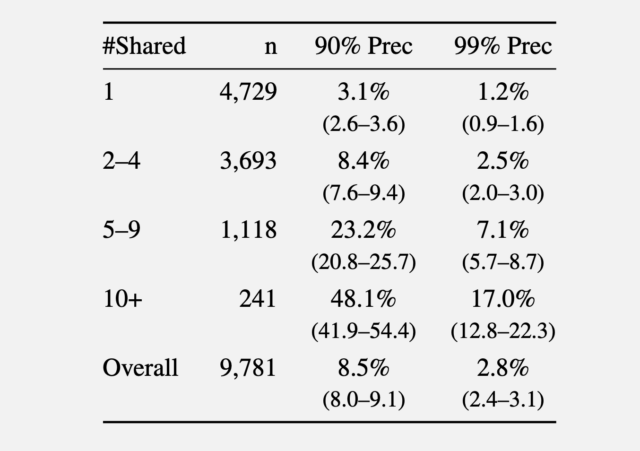
أذكر عند عتبات الدقة المختلفة.
أذكر عند عتبات الدقة المختلفة.
وفي تجربة ثالثة، أخذ الباحثون مجموعة من 5000 مستخدم لموقع Reddit. أضاف الباحثون 5000 هوية “لتشتيت الانتباه” لمستخدمي Reddit إلى مجموعة المرشحين. قارن الباحثون طريقتهم بالهجوم الأقدم على جائزة Netflix. ثم قاموا بإضافة 5000 ملف تعريف للمرشحين إلى القائمة التي تضم 10000 ملف تعريف للمرشحين، بما في ذلك المستخدمين الذين يظهرون فقط في مجموعة استعلام، مع عدم وجود تطابق حقيقي في مجموعة المرشحين.



